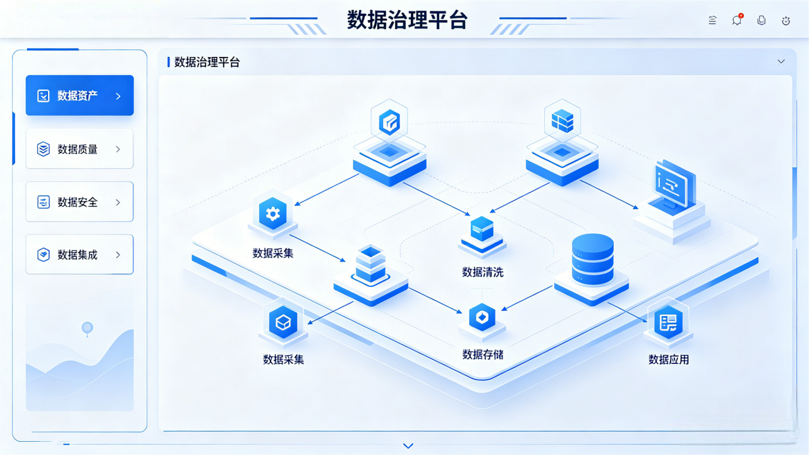
解决方案
-
 AI通信智算中心行动环监测|运维监控|机房孪生
AI通信智算中心行动环监测|运维监控|机房孪生 -
 AI智能巡检机器人具身智能|巡检|应急安全
AI智能巡检机器人具身智能|巡检|应急安全 -
 数字孪生工厂生产透明化|孪生复现|一体化管控
数字孪生工厂生产透明化|孪生复现|一体化管控 -
 智慧仓储全流程一体化|仓储整体解决方案
智慧仓储全流程一体化|仓储整体解决方案 -
 智慧矿山矿山全流程的智能化运行
智慧矿山矿山全流程的智能化运行 -
 智慧油田自主研发的油田数字孪生云平台
智慧油田自主研发的油田数字孪生云平台 -
 智慧能源管理驱动高效用能,开启低碳未来
智慧能源管理驱动高效用能,开启低碳未来 -
 AI应急管控中心态势感知|应急指挥|智能决策
AI应急管控中心态势感知|应急指挥|智能决策 -
 管理驾驶舱全面指标|决策支持|可视化
管理驾驶舱全面指标|决策支持|可视化 -
 智慧园区园区管理|决策协同|运营效率
智慧园区园区管理|决策协同|运营效率 -
 数字化展馆一键换馆、多端延伸,以实时数据驱动企业发展及数字化转型升级
数字化展馆一键换馆、多端延伸,以实时数据驱动企业发展及数字化转型升级 -
 智慧云展厅线上展厅|产品拆装|品牌直播
智慧云展厅线上展厅|产品拆装|品牌直播 -
 AI智能模拟器智能助手|无序化操作
AI智能模拟器智能助手|无序化操作 -
 虚拟仿真培训设备原理|拆装|维修
虚拟仿真培训设备原理|拆装|维修 -
 航空航天缩短研制周期|优化装配工艺|降低实装损耗|全生命周期运维
航空航天缩短研制周期|优化装配工艺|降低实装损耗|全生命周期运维